Signature in the Cell
Intelligent Design and the DNA Enigma Published in The Blackwell Companion to Science and ChristianityWhen James Watson and Francis Crick elucidated the structure of DNA in 1953, they solved one mystery but created another.
For almost 100 years after the publication of Charles Darwin’s The Origin of Species, biology had rested secure in the knowledge that it had explained one of humankind’s most enduring enigmas. From ancient times, observers had noticed organized structures in living organisms that gave the appearance of having been designed for a purpose — the elegant form and protective covering of the coiled nautilus, the interdependent parts of the eye, the interlocking bones, muscles and feathers of a bird wing.
But with the advent of Darwinism, and later neo-Darwinism, modern science claimed to explain the appearance of design in life as the product of a purely undirected process. In the Origin, Darwin argued that the striking appearance of design in living organisms — in particular, the way they are so well adapted to their environments — could be explained by natural selection working on random variations, a purely undirected process that nevertheless mimicked the powers of a designing intelligence. Thus, as evolutionary biologist Francisco Ayala (2007, 8567) notes, Darwin accounted for “design without a designer.” Indeed, since 1859 the appearance of design in living things has been understood by most biologists to be an illusion — a powerfully suggestive illusion but an illusion nonetheless. Or as Francis Crick put, biologists must “constantly keep in mind that what they see was not designed, but rather evolved” (Crick 1988, 138).
But due in large measure to Watson and Crick’s own discovery of the information-bearing properties of DNA, scientists have become increasingly, and in some quarters, acutely aware that there is at least one appearance of design in biology that has not been explained by natural selection or any other purely naturalistic mechanism. When Watson and Crick discovered the structure of DNA, they also discovered that DNA stores information in the form of a four-character alphabetic code. Strings of precisely sequenced chemicals called nucleotide bases store and transmit the assembly instructions — the information — for building the crucial protein molecules and protein machines the cell needs to survive.
Crick later developed this idea with his famous “sequence hypothesis,” according to which the chemical parts of DNA (the nucleotide bases) function like letters in a written language or symbols in a computer code. Just as letters in an English sentence or digital characters in a computer program may convey information depending on their arrangement, so too do certain sequences of chemical bases along the spine of the DNA molecule convey precise instructions for building proteins.
Moreover, DNA sequences do not just have a mathematically measurable degree of improbability. Thus, they do not just possess “information” in the strictly mathematical sense of the theory of information developed by the famed M.I.T. scientist Claude Shannon in the late 1940s. Instead, DNA contains information in the richer and more ordinary dictionary sense of “alternative sequences or arrangements of characters that produce a specific effect.” DNA base sequences convey instructions. They perform functions and produce specific effects. Thus, they do not possess mere “Shannon information,” but instead what has been called “specified” or “functional information.” Indeed, like the precisely arranged zeros and ones in a computer program, the chemical bases in DNA convey instructions in virtue of their “specificity” of arrangement. Thus, Richard Dawkins (1995, 17) notes that, “the machine code of the genes is uncannily computer-like” and software developer Bill Gates (1995, 188) observes that “DNA is like a computer program.” Similarly, biotechnology specialist Leroy Hood (2003, 444-448) describes the information stored in DNA as “digital code.”
But if this is true, how did the functionally specified information in DNA arise? Is this striking appearance of design the product of actual design or a natural process that can mimic the powers of a designing intelligence? This question is related to a longstanding mystery in biology — the question of the origin of the first life. Indeed, since Watson and Crick’s discovery, scientists have increasingly come to understand the centrality of information to even the simplest living systems.DNA stores the assembly instructions for building the many crucial proteins and protein machines that service and maintain even the most primitive one-celled organisms. It follows that building a living cell in the first place requires assembly instructions stored in DNA or some equivalent molecule. As origin-of-life researcher Bernd-Olaf Küppers (1990, 170-172) has explained, “The problem of the origin-of-life is clearly basically equivalent to the problem of the origin of biological information.”
Today the question of how life first originated is widely regarded as a profound and unsolved scientific problem, largely because of the mystery surrounding the origin of functionally specified biological information. This essay will examine the various attempts that have been made to solve this mystery — what I call “the DNA enigma” — and it will argue that intelligent design, rather than an undirected mechanism that merely mimics design, best explains it.
Early Theories of the Origin of Life
Darwin’s theory sought to explain the origin of new forms of life from simpler forms. It did not explain how the first life — presumably a simple one-celled organism — might have arisen to begin with. Nevertheless, in the 1860s and 1870s scientists assumed that devising a materialistic explanation for the origin of life would be fairly easy and, therefore, they did not worry that one-celled organisms might betray evidence of design.
Instead, scientists at the time assumed that life was essentially a rather simple substance called protoplasm that could be easily constructed by combining and recombining simple chemicals such as carbon dioxide, oxygen, and nitrogen. German evolutionary biologist Ernst Haeckel likened cell “autogeny,” as he called it, to the process of inorganic crystallization. Haeckel’s English counterpart, T.H. Huxley, proposed a simple two-step method of chemical recombination to explain the origin of the first cell. Just as salt could be produced spontaneously by adding sodium to chloride, so they thought could a living cell be produced by adding several chemical constituents together and then allowing spontaneous chemical reactions produce the simple protoplasmic substance that they assumed to be the essence of life (Meyer 1990, 143-161).
During the 1920s and 1930s a more sophisticated version of this “chemical evolutionary theory” was proposed by a Russian biochemist named Alexander I. Oparin. Oparin, like his 19th-century predecessors, suggested that life could have first evolved as the result of a series of chemical reactions. Nevertheless, he envisioned that this process of chemical evolution would involve many more chemical transformations and reactions and hundreds of millions of years. Oparin postulated these additional steps and additional time because he had a more accurate understanding of the complexity of cellular metabolism than did Haeckel and Huxley (Kamminga 1980, 222-245). Nevertheless, neither he, nor any one else in the 1930s, fully appreciated the complexity — and information-bearing properties — of the DNA, RNA and proteins that make life possible.
Though Oparin’s theory appeared to receive experimental support in 1953 when Stanley Miller simulated the production of the amino acid “building blocks” of proteins under ostensibly pre-biotic atmospheric conditions, his textbook version of chemical evolutionary theory is riddled with difficulties. Miller’s simulation experiment is now understood by origin-of-life researchers to have little, if any, relevance to explaining how amino acids — let alone their precise sequencing which is necessary to produce proteins — could have arisen in the actual atmosphere of the early earth. Moreover, Oparin proposed no explanation for the origin of the information in DNA (or RNA) that present-day cells use to build proteins. As a result, a search for pre-biotic chemical mechanisms to explain the origin of biological information has ensued. Since the 1950s, three broad types of naturalistic explanations have been proposed by scientists in an attempt to explain the origin of the information necessary to produce the first cell.
Beyond the Reach of Chance
One naturalistic view of the origin of life is that it happened exclusively by chance (Wald 1954, 44-53). Since the late 1960s, however, few serious scientists have supported this view (Shapiro 1986, 121; Kamminga 1980, 303-304). Since molecular biologists began to understand how the digital information in DNA directs the construction of protein synthesis in the cell, many calculations have been made to determine the probability of formulating functional proteins and nucleic acids (DNA or RNA molecules) at random. Even assuming extremely favorable pre-biotic conditions (whether realistic or not) and theoretically maximal reaction rates, such calculations have invariably shown that the probability of obtaining functionally sequenced (information-rich) bio-macromolecules at random is, in the words of physicist Ilya Prigogine and his colleagues (1972, 23), “vanishingly small … even on the scale of … billions of years.”
Even so, origin-of-life scientists recognize that the critical problem is not just generating an improbable sequence of chemical constituents — an improbable arrangement of nucleotide bases in DNA, for example. Instead, the problem is relying on a random search or shuffling of molecular building blocks to generate one of the very rare arrangements of bases in DNA (or amino acids in proteins) that also perform a biological function.Very improbable things do occur by chance. Any hand of cards or any series of rolled dice represents an improbable occurrence. Observers often justifiably attribute such events to chance alone. What justifies the elimination of chance is not just the occurrence of a highly improbable event but also the occurrence of an improbable event that conforms to a discernible pattern (either what statisticians call a “conditionally independent pattern” or what I call a “functionally significant pattern,” i.e., one that accomplishes a discernable purpose).
If, for example, someone repeatedly rolls two dice and turns up a sequence such as 9, 4, 11, 2, 6, 8, 5, 12, 9, 6, 8, and 4, no one will suspect anything but the interplay of random forces, though this sequence does represent a very improbable event given the number of possible numeric sequences that exist corresponding to a sequence of this length. Yet rolling 12 (or 1200!) consecutive sevens in a game that rewards sevens will justifiably arouse suspicion that something more than chance is in play.
Origin-of-life researchers employ this kind of statistical reasoning to justify the elimination of the chance hypothesis. Christian de Duve (1995a, 437), for example, has made this logic explicit in order to explain why chance fails as an explanation for the origin of life: “A single, freak, highly improbable event can conceivably happen. Many highly improbable events – drawing a winning lottery number or the distribution of playing cards in a hand of bridge – happen all the time. But a string of improbable events – drawing the same lottery number twice, or the same bridge hand twice in a row – does not happen naturally.”
In my book, Signature in the Cell, I perform updated calculations of the probability of the origin of even a single functional protein or corresponding functional gene (the section of a DNA molecule that directs the construction of a particular protein) by chance alone. My calculations are based upon recent experiments in molecular biology establishing the extreme rarity of functional proteins in relation to the total number of possible arrangements of amino acids corresponding to a protein of a given length. I show that the probability of producing even a single functional protein (a gene product) of modest length (150 amino acids) by chance alone stands at a “vanishingly small” 1 chance in 10164.
Moreover, in Signature, I not only demonstrate that the probability of a single functional protein arising at any given time is absurdly small, but also that the probability is even extremely small in relation to all the opportunities that have existed for that event to occur since the beginning of time (what are called the “probabilistic resources” of the universe). I show that even if every event in the entire history of the universe (where an event is defined minimally as an interaction between elementary particles) were devoted to producing combinations of amino acids of a given length (an extravagantly generous assumption), the number of combinations thus produced would still represent a tiny portion — less than 1 out of a trillion trillion — of the total number of possible amino acid combinations corresponding to a functional protein — any functional protein — of that given length. In short, it is extremely unlikely that even a single protein would have arisen by chance on the early Earth even taking the probabilistic resources of the entire universe into account. For this and other similar reasons, serious origin-of-life researchers now consider “chance” an inadequate causal explanation for the origin of biological information (de Duve 1996, 112; Crick 1981, 89-93).
Self-Organization Scenarios
Because of these difficulties, many origin-of-life theorists after the mid 1960s addressed the problem of the origin of biological information in a different way. Rather than invoking chance events or “frozen accidents,” many theorists suggested that the laws of nature or law-like forces of chemical attraction might have generated the information in DNA and proteins. Some have suggested that simple chemicals might possess “self-ordering properties” capable of organizing the constituent parts of proteins, DNA and RNA into the specific arrangements they now possess. Just as electrostatic forces draw sodium (Na+) and chloride ions (Cl-) together into a highly-ordered patterns within a crystal of salt (NaCl), so too might amino acids with special affinities for each other arrange themselves to form proteins. Kenyon and Steinman (1969) developed this idea in a book entitled Biochemical Predestination.
Prigogine and Nicolis (1977, 339-53, 429-47) proposed another theory of self-organization based on their observation that open systems driven far from equilibrium often display self-ordering tendencies. For example, gravitational energy will produce highly ordered vortices in a draining bathtub; and thermal energy flowing through a heat sink will generate distinctive convection currents or “spiral wave activity.”
For many current origin-of-life scientists, self-organizational models now seem to offer the most promising approach to explaining the origin of biological information. Nevertheless, critics have called into question both the plausibility and the relevance of such models. Ironically, perhaps the most prominent early advocate of self-organization, Dean Kenyon, has now explicitly repudiated his own and similar theories as both incompatible with empirical findings and theoretically incoherent.
The difficulty using self-organizational scenarios to explain the origin of biological information can be illustrated by examining the structure of the DNA molecule. The diagram below shows that the structure of DNA depends upon several chemical bonds. There are bonds, for example, between the sugar molecules (designated by the pentagons) and the phosphate molecules (designated by the circled Ps) that form the twisting backbones of the DNA helix. There are bonds fixing individual (nucleotide) bases to the sugar-phosphate backbones on each side of the molecule. Notice, however, that there are no chemical bonds (and thus forces of attraction), between the bases that run along the spine of the helix. Yet it is precisely along this axis of the molecule that the genetic instructions in DNA are encoded.
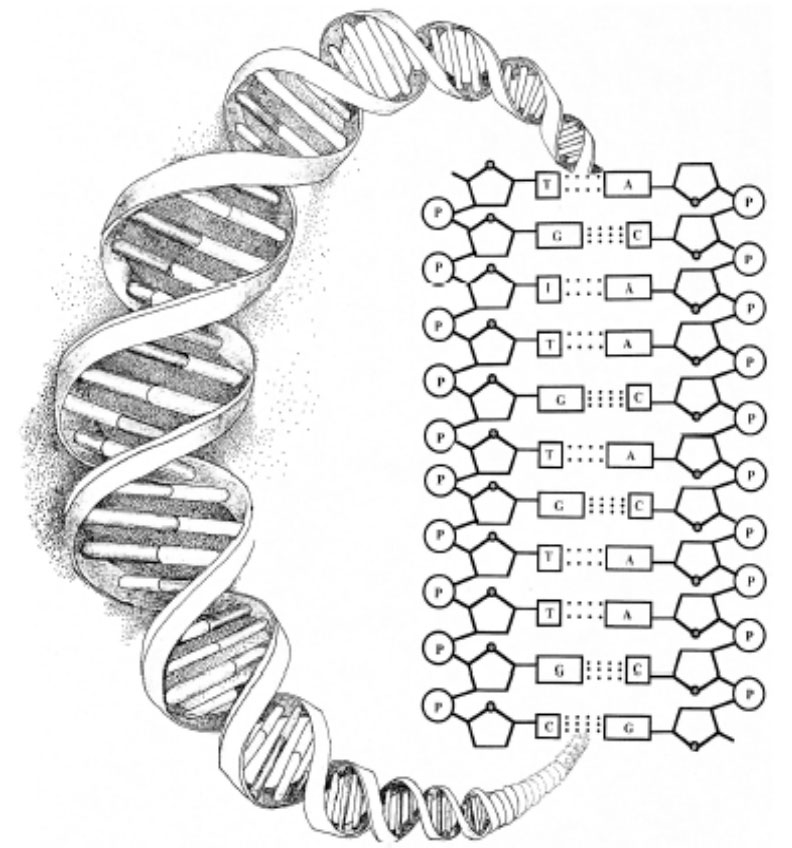
Further, just as magnetic letters can be combined and recombined in any way to form various sequences on a metal surface, so too can each of the four bases A, T, G, and C attach to any site on the DNA backbone with equal facility, making all sequences equally probable (or improbable). The same type of chemical bond (an N-glycosidic bond) occurs between the bases and the backbone regardless of which base attaches. All four bases are acceptable; none is preferred. Thus, differences in bonding affinity do not determine the arrangement of the bases—that is, forces of chemical attraction do not account for the information in DNA.
For those who want to explain the origin of life as the result of self-organizing properties intrinsic to the material constituents of living systems, these rather elementary facts of molecular biology have devastating implications. The most logical place to look for self-organizing properties to explain the origin of genetic information is in the constituent parts of the molecules carrying that information. But biochemistry and molecular biology make clear that the forces of attraction between the constituents in DNA (and RNA) do not explain the sequence specificity (the information) present in these large information-bearing molecules.
Significantly, information theorists insist that there is a good reason for this. If chemical affinities between the bases in the DNA instruction set determined the arrangement of the bases, such affinities would dramatically diminish the capacity of DNA to carry information. Consider what would happen if the individual nucleotide “letters” (A, T, G, C) in a DNA molecule did interact by chemical necessity with each other. Suppose every time adenine (A) occurred in a growing genetic sequence, it dragged guanine (G) along with it. And every time cytosine (C) appeared, thymine (T) would follow. As a result, the DNA message text would be peppered with repeating sequences of A’s followed by G’s and C’s followed by T’s.
Rather than having a genetic molecule capable of unlimited novelty, with all the unpredictable and aperiodic sequences that characterize informative texts, we would have a highly repetitive text awash in redundant sequences — much as happens in crystals. Indeed, in a crystal the forces of mutual chemical attraction do completely explain the sequential ordering of the constituent parts, and consequently crystals cannot convey novel information. For this reason, bonding affinities, to the extent they exist, cannot be used to explain the origin of information. Self-organizing chemical affinities create mantras, not messages.
The tendency to confuse the qualitative distinction between “order” and “information” has characterized self-organizational research efforts and calls into question the relevance of such work to the origin of life. Self-organizational theorists explain well what doesn’t need explaining. What needs explaining is not the origin of order (whether in the form of the repetitive sequences of chemical constituents in crystals, or the symmetrical patterns evident in swirling tornadoes or the “eyes” of hurricanes), but the origin of information — the highly improbable, aperiodic, and yet specified sequences that make biological function possible (Yockey 1992, 274-281).
Chance and Necessity: Prebiotic Natural Selection
Of course, many theories of chemical evolution have not relied exclusively on either chance or law-like necessity alone, but have instead attempted to combine the two types of explanations. For example, after 1953 Oparin revised his original theory of chemical evolution. In so doing, he attempted to explain the origin of biological information as the product of the law-like process of natural selection acting on the chance interactions of simple non-living molecules. Yet Oparin’s notion of pre-biotic natural selection soon encountered obvious difficulties.
First, the process of natural selection presupposes the differential reproduction of living organisms and thus a pre-existing mechanism of self-replication. Yet, self-replication in all extant cells depends upon functional (and, therefore, to a high degree sequence-specific, information-rich) proteins and nucleic acids. Yet the origin of such information-rich molecules is precisely what Oparin needed to explain. Thus, many rejected his postulation of pre-biotic natural selection as question begging. As the evolutionary biologist Theodosius Dobzhansky (1965, 310) insisted, “pre-biological natural selection is a contradiction in terms.” Or as Christian de Duve (1991, 187) has explained, theories of pre-biotic natural selection “need information which implies they have to presuppose what is to be explained in the first place.”
The RNA World
More recently, some have claimed that another scenario — the RNA World hypothesis, combining chance and pre-biotic natural selection — can solve the origin-of-life problem and with it, presumably, the problem of the origin of genetic information. The RNA world was proposed as an explanation for the origin of the interdependence of nucleic acids and proteins in the cell’s information-processing system. In extant cells, building proteins requires genetic information from DNA, but information in DNA cannot be processed without many specific proteins and protein complexes. This poses a chicken-or-egg problem. The discovery that RNA (a nucleic acid) possesses some limited catalytic properties similar to those of proteins suggested a way to solve that problem. “RNA-first” advocates proposed an early state in which RNA performed both the enzymatic functions of modern proteins and the information-storage function of modern DNA, thus allegedly making the interdependence of DNA and proteins unnecessary in the earliest living system.
Nevertheless, many fundamental difficulties with the RNA-world scenario have emerged. First, synthesizing (and/or maintaining) many essential building blocks of RNA molecules under realistic conditions has proven either difficult or impossible (Shapiro 1999, 4396-401). Second, naturally occurring RNA possesses very few of the specific enzymatic properties of proteins necessary to extant cells. Indeed, RNA catalysts do not function as true enzyme catalysts. Enzymes are capable of coupling energetically favorable and energetically unfavorable reactions together. RNA catalysts, so-called “ribozymes,” are not. Third, RNA-world advocates offer no plausible explanation for how primitive RNA replicators might have evolved into modern cells that do rely almost exclusively on proteins to process and translate genetic information and regulate metabolism (Wolf and Koonin 2007, 14). Fourth, attempts to enhance the limited catalytic properties of RNA molecules in so-called ribozyme engineering experiments have inevitably required extensive investigator manipulation, thus simulating, if anything, the need for intelligent design, not the efficacy of an undirected chemical evolutionary process.
Most importantly for our present considerations, the RNA-world hypothesis presupposes, but does not explain, the origin of sequence specificity or information in the original functional RNA molecules. Indeed, the RNA-world scenario was proposed as an explanation for the functional interdependence problem, not the information problem. Even so, some RNA-world advocates seem to envision leapfrogging the sequence-specificity problem. They imagine sections of RNA arising by chance on the pre-biotic earth and then later acquiring an ability to make copies of themselves – that is, to self-replicate. In such a scenario, the capacity to self-replicate would favor the survival of those RNA molecules that could do so and would thus favor the specific sequences that the first self-replicating molecules happened to have.
This suggestion merely shifts the information problem out of view, however. To date scientist have been able to design RNA catalysts that will copy only about 10% of themselves (Johnston et al. 2001, 1319-25). For strands of RNA to perform even this limited replicase (self-replication) function, however, they must, like proteins, have very specific arrangements of constituent building blocks (nucleotides in the RNA case). Further, the strands must be long enough to fold into complex three-dimensional shapes (to form so-called tertiary structures). Thus, any RNA molecule capable of even limited function must have possessed considerable (specified) information content. Yet explaining how the building blocks of RNA arranged themselves into functionally specified sequences has proven no easier than explaining how the constituent parts of DNA might have done so, especially given the high probability of destructive cross-reactions between desirable and undesirable molecules in any realistic pre-biotic soup. As de Duve (1995b, 23) has noted in a critique of the RNA-world hypothesis, “hitching the components together in the right manner raises additional problems of such magnitude that no one has yet attempted to do so in a prebiotic context.”
The Return of the Design Hypothesis
If attempts to solve the information problem only relocate it, and if neither chance nor physical-chemical necessity, nor the two acting in combination, explains the ultimate origin of specified biological information, what does? Do we know of any entity that has the causal powers to create large amounts of specified information? We do. As information scientist Henry Quastler (1964, 16) recognized, the “creation of new information is habitually associated with conscious activity.”
Experience affirms that functionally specified information routinely arises from the activity of intelligent agents. A computer user who traces the information on a screen back to its source invariably comes to a mind, that of a software engineer or programmer. Similarly, the information in a book or newspaper column ultimately derives from a writer – from a mental, rather than a strictly material, cause.
But could this intuitive connection between information and the prior activity of a designing intelligence justify a rigorous scientific argument for intelligent design? I first began to consider this possibility during my Ph.D. research at Cambridge University in the late 1980s. At that time, I was examining how scientists investigating origins events developed their arguments. Specifically, I examined the method of reasoning that historical scientists use to identify causes responsible for events in the remote past.
I discovered that historical scientists often make inferences with a distinctive logical form (known technically as abductive inferences, Peirce 1931, 372-88). Paleontologists, evolutionary biologists and other historical scientists reason like detectives and infer past conditions or causes from present clues. As Stephen Jay Gould (1986, 61) notes, historical scientists typically “infer history from its results.”
Nevertheless, as many philosophers have noted there is a problem with this kind of historical reasoning, namely, there is often more than one cause that can explain the same effect. This makes reasoning from present clues (circumstantial evidence) tricky because the evidence can point to more than one causal explanation or hypothesis. To address this problem in geology, the 19th-century geologist Thomas Chamberlain (1890, 92-96)delineated a method of reasoning he called “the method of multiple working hypotheses.”
Contemporary philosophers of science such as Peter Lipton (1991, 1) have called this the method of “inference to the best explanation.” That is, when trying to explain the origin of an event or structure from the past, scientists often compare various hypotheses to see which would, if true, best explain it (Lipton 1991, 1). They then provisionally affirm the hypothesis that best explains the data as the one that is most likely to be true. But that raised an important question: exactly what makes an explanation best?
As it happens, historical scientists have developed criteria for deciding which cause, among a group of competing possible causes, provides the best explanation for some event in the remote past. The most important of these criteria is called “causal adequacy.” This criterion requires that historical scientists, as a condition of a successful explanation, identify causes that are known to have the power to produce the kind of effect, feature or event that requires explanation. In making these determinations, historical scientists evaluate hypotheses against their present knowledge of cause and effect. Causes that are known to produce the effect in question are judged to be better candidates than those that are not. For instance, a volcanic eruption provides a better explanation for an ash layer in the earth than an earthquake because eruptions have been observed to produce ash layers, whereas earthquakes have not.
One of the first scientists to develop this principle was the geologist Charles Lyell who also influenced Charles Darwin. Darwin read Lyell’s magnum opus, The Principles of Geology, on the voyage of the Beagle and employed its principles of reasoning in The Origin of Species. The subtitle of Lyell’s Principles summarized the geologist’s central methodological principle: Being an Attempt to Explain the Former Changes of the Earth’s Surface, by Reference to Causes Now in Operation (1800-1803). Lyell argued that when scientists seek to explain events in the past, they should not invoke unknown or exotic causes, the effects of which we do not know. Instead they should cite causes that are known from our uniform experience to have the power to produce the effect in question (see Lyell 1800-1803, vol. 1, 75-91). Historical scientists should cite “causes now in operation” or presently acting causes. This was the idea behind his uniformitarian principle and the dictum: “The present is the key to the past.” According to Lyell, our present experience of cause and effect should guide our reasoning about the causes of past events. Darwin himself adopted this methodological principle as he sought to demonstrate that natural selection qualified as a vera causa, that is, a true, known or actual cause of significant biological change (Kavalovski 1974, 78-103.)He sought to show that natural selection was “causally adequate” to produce the effects he was trying to explain.
Both philosophers of science and leading historical scientists have emphasized causal adequacy as the key criterion by which competing hypotheses are adjudicated. But philosophers of science also have noted that assessments of explanatory power lead to conclusive inferences only when it can be shown that there is only one known cause for the effect or evidence in question (Scriven 1959, 480). When scientists can infer a uniquely plausible cause, they can avoid the fallacy of affirming the consequent and the error of ignoring other possible causes with the power to produce the same effect (Meyer 1990, 96-108).
Intelligent Design as the Best Explanation?
What did all this have to do with the DNA enigma? As a Ph.D. student I wondered if a case for an intelligent cause could be formulated and justified in the same way that historical scientists would justify any other causal claim about an event in the past. My study of historical scientific reasoning and origin-of-life research suggested to me that it was possible to formulate a rigorous scientific case for intelligent design as an inference to the best explanation, specifically, as a best explanation for the origin of biological information. The action of a conscious and intelligent agent clearly represents a known (presently acting) and adequate cause for the origin of information. Uniform and repeated experience affirms that intelligent agents produce information-rich systems, whether software programs, ancient inscriptions, or Shakespearean sonnets. Minds are clearly capable of generating functionally specified information.
Further, the functionally specified information in the cell also points to intelligent design as the best explanation for the ultimate origin of biological information. Why? Experience shows that large amounts of such information (especially codes and languages) invariably originate from an intelligent source—from a mind or a personal agent. In other words, intelligent activity is the only known cause of the origin of functionally specified information (at least, starting from a non-living source, that is, from purely physical or chemical antecedents). Since intelligence is the only known cause of specified information in such a context, the presence of functionally specified information sequences in even the simplest living systems points definitely to the past existence and activity of a designing intelligence.
Ironically, this generalization – that intelligence is the only known cause of specified information (starting from a non-biological source) – has received support from origin-of-life research itself. During the last fifty years, every naturalistic model proposed has failed to explain the origin of the functionally specified genetic information required to build a living cell (Thaxton, Bradley and Olsen 1984, 42-172; Shapiro 1986; Dose 1988, 348-56; Yockey 1992, 259-93; Thaxton and Bradley 1994, 193-97; Meyer 2009). Thus, mind or intelligence, or what philosophers call “agent causation,” now stands as the only cause known to be capable of generating large amounts of information starting from a nonliving state. As a result, the presence of specified information-rich sequences in even the simplest living systems would seem to imply intelligent design.
When I first noticed the subtitle of Lyell’s book, referring us to “causes now in operation,” a light came on for me. I immediately asked myself a question: “What causes ‘now in operation’ produce digital code or specified information?” Is there a known cause—a vera causa—of the origin of such information? What does our uniform experience tell us? As I thought about this further, it occurred to me that by Lyell’s and Darwin’s own rule of reasoning and test of a sound scientific explanation, intelligent design must qualify as the currently best scientific explanation for the origin of biological information. Why? Because we have independent evidence—“uniform experience”—that intelligent agents are capable of producing specified information and, as origin-of-life research itself has helped to demonstrate, we know of no other cause capable of producing functional specified information starting from a purely physical or chemical state.
Scientists in many fields recognize the connection between intelligence and information and make inferences accordingly. Archaeologists assume that a scribe produced the inscriptions on the Rosetta stone. The search for extraterrestrial intelligence (SETI) presupposes that any specified information imbedded in electromagnetic signals coming from space would indicate an intelligent source (McDonough 1987). As yet, radio astronomers have not found any such information-bearing signals. But closer to home, molecular biologists have identified information-rich sequences and systems in the cell, suggesting, by the same logic, the past existence of an intelligent cause for those effects.
Indeed, our uniform experience affirms that specified information—whether inscribed in hieroglyphics, written in a book, encoded in a radio signal, or produced in an RNA world ribozyme engineering experiment—always arises from an intelligent source, from a mind and not a strictly material process. So the discovery of the functionally specified digital information in the DNA molecule provides strong grounds for inferring that intelligence played a role in the origin of DNA. Indeed, whenever we find specified information and we know the causal story of how that information arose, we always find that it arose from an intelligent source. It follows thatthe best, most likely explanation for the origin of the specified, digitally encoded information in DNA is that it too had an intelligent source. Intelligent design best explains the DNA enigma.
Postscript: In Signature in the Cell: DNA and the Evidence for Intelligent Design (HarperOne 2009), I respond in detail to various objections to the case for intelligent design sketched in this short article. I address objections such as: “intelligent design (a) is religion, (b) is not science, (c) makes no predictions, (d) is based on flawed analogical reasoning, (e) is a fallacious argument from ignorance,” and many others. I direct intrigued, but still skeptical, readers to my book for a more thorough consideration of popular objections to my argument. I also provide more extensive documentation there of the scientific discussion provided in this paper.
Bibliography
- Ayala, Francisco J. “Darwin’s greatest discovery: Design without designer,” Proceedings of the National Academy of Sciences 104 (2007): 8567-8573.
- Chamberlain, Thomas C., 1890. “The method of multiple working hypotheses.” Science (old series) 15, pp. 92-96. Reprinted in Science 148(1965), pp. 754-759.
- Crick, Francis, 1981. Life itself. New York: Simon & Schuster.
- Dawkins, Richard, 1995. River out of Eden: a Darwinian view of life. New York: Basic.
- de Duve, Christian, 1991. Blueprint for a cell: the nature and origin of life. Burlington, N.C.: Neil Patterson Publishers.
- de Duve, Christian, 1995a. The beginnings of life on Earth. American Scientist 83, pp. 249-50, 428-37.
- de Duve, Christian, 1995b. Vital dust: life as a cosmic imperative. New York: Basic.
- de Duve, Christian, 1996. The constraits of chance. Scientific American, Jan., p. 112.
- Dobzhansky, Theodosius, 1965. “Discussion of G. Schramm’s paper.” In: Sidney W. Fox, ed. The origins of prebiological systems and of their molecular matrices. New York: Academic Press, pp. 309-15.
- Dose, K., 1988. The origin of life: more questions than answers. Interdisciplinary Science Review 13, pp. 348-56.
- Gates, Bill, 1995. The road ahead. New York: Viking.
- Gould, Stephen Jay, 1986. Evolution and the triumph of homology: or, why history matters. American Scientist 74, pp. 60-69.
- Hood, Leroy; Galas, David, 2003. The digital code of DNA. Nature 421, pp. 444-448.
- Johnston, Wendy K.; Unrau, Peter J.; Lawrence, Michael S.; Glasner, Margaret E. and Bartel, David P., 2001. RNA-catalyzed RNA polymerization: accurate and general RNA-templated primer extension. Science 292, pp. 1319-25.
- Kamminga, Harmke, 1980. Studies in the history of ideas on the origin of life. Ph.D. University of London.
- Kavalovski, V., 1974. The vera causa principle: a historico-philosophical study of a meta-theoretical concept from Newton through Darwin. Ph.D. University of Chicago.
- Kenyon, Dean and Gary Steinman, 1969. Biochemical Predestination. New York: McGraw-Hill, 1969).
- Küppers, Bernd-Olaf, 1990. Information and the origin of life. Cambridge: MIT Press.
- Lipton, Peter, 1991. Inference to the best explanation. London and New York: Routledge.
- Lyell, Charles, 1830-1833. Principles of Geology: being an attempt to explain the former changes of the Earth’s surface, by reference to causes now in operation. 3 vols. London: John Murray.
- McDonough, T. R., 1987. The search for extraterrestrial intelligence: listening for life in the cosmos. New York: Wiley.
- Meyer, Stephen C., 1990. Of clues and causes: a methodological interpretation of origin of life studies.Ph.D. Cambridge University.
- Meyer, Stephen C., 2009. Signature in the cell: DNA and the evidence for intelligent design. San Francisco: HarperOne.
- Peirce, Charles S., 1931. Collected papers, edited by C. Hartshorne and P. Weiss, Cambridge: Harvard University Press, vol. 2, pp. 372-88.
- Prigogine, Ilya; Nicolis, Grégoire; and Babloyantz, Agnessa, 1972. Thermodynamics of evolution. Physics Today, 23 Nov., pp. 23-31.
- Prigogine, Ilya and G. Nicolis. Self Organization in Nonequilibrium Systems. New York: Wiley, (1977): 339-53, 429-47.
- Quastler, Henry, 1964. The emergence of biological organization. New Haven: Yale University Press.
- Scriven, Michael, 1959. Explanation and prediction in evolutionary theory. Science 130, pp. 477-82.
- Shapiro, Robert, 1986. Origins: A skeptic’s guide to the creation of life on Earth. New York: Summit Books.
- Shapiro, Robert, 1999. Prebiotic cytosine synthesis: a critical analysis and implications for the origin of life, Proceedings of the National Academy of Sciences, USA 96, pp. 4396–4401
- Thaxton, Charles; and Bradley, Walter L., 1994. Information and the origin of life. In J. P. Moreland, ed. The creation hypothesis: scientific evidence for an intelligent designer. Downers Grove, Ill.: InterVarsity Press, pp. 173–210.
- Thaxton, Charles; Bradley, Walter L.; and Olsen, Roger, 1984. The mystery of life’s origin. New York: Philosophical Library.
- Wald, G., 1954. The origin of life. Scientific American 191, pp. 44-53.
- Wolf, Huri I. and Koonin, Eugene V. On the origin of the translation system and the genetic code in the RNA world by means of natural selection, exaptation, and subfunctionalization. Biology Direct 2, pp. 1-25.
- Yockey, Hubert P., 1992. Information theory and molecular biology. Cambridge: Cambridge University Press.