
Jonathan Bartlett is a senior software R&D engineer at Specialized Bicycle Components, where he focuses on solving problems that span multiple software teams. Previously he was a senior developer at ITX, where he developed applications for companies across the US. He also offers his time as the Director of The Blyth Institute, focusing on the interplay between mathematics, philosophy, engineering, and science. Jonathan is the author of several textbooks and edited volumes which have been used by universities as diverse as Princeton and DeVry.
Archives

Online Training: Real Education or Going Through the Motions?
Not all online trainings are bad. But many are procedural and pointless.
The Information Age Has Forgotten Formation
We need more than mere information. We need practices, habits, and experiences that will positively shape who we become.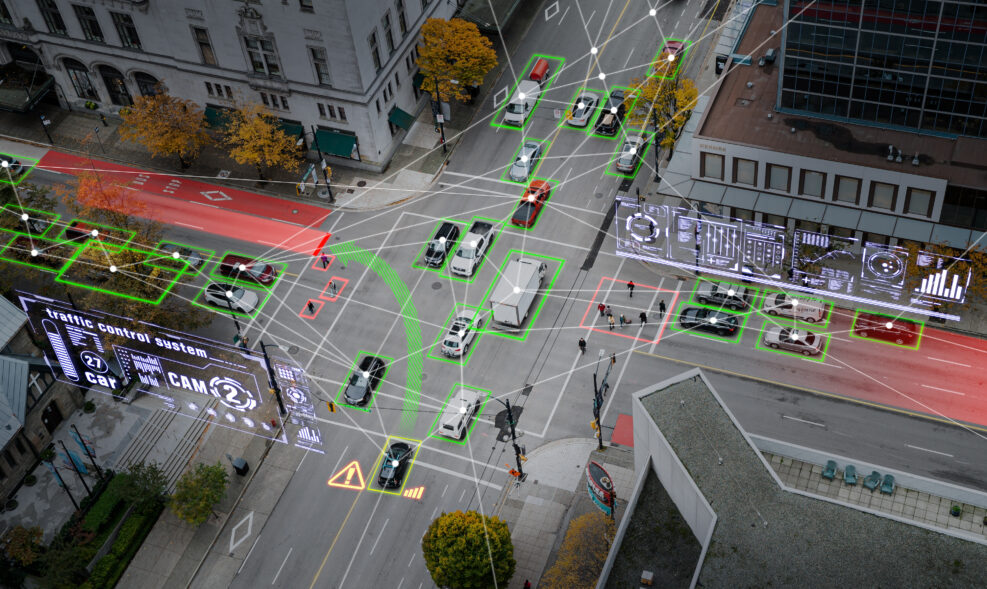
Autonomous Vehicles Are Catching Up Fast
There are winners and losers. GM's Cruise was kicked out of California over safety issues but Alphabet's Waymo, which emphasizes safety, is still chugging along
Framework for AI Legislation
Unfortunately, current calls for AI legislation seems to be largely motivated by fear of the unknown rather than looking for specific policy goals.
Copyright in the Age of Artificial Intelligence
What exactly is a human and how does a human differ from a computer?
Directed Goals in Living and Evolving Systems
Nearly every action that an organism does is for something.
Why Build Process Automation Matters
Automated build processes allow for the standardization and systematization of your development pipeline.Uber Achieves Profitability After Giving Up Self-Driving
The alternative taxi service has finally parted ways with its self-driving unit
Of Infinity and Beyond
What are the problems and solutions with infinity in mathematics?
Why Is Object-Oriented Programming Popular?
This method makes programmers think more systematically about their code
The Microservices Controversy from a Software Management Perspective
As projects get bigger, so do the reasons for having a microservice architecture
The Raspberry Pi Phenomenon
A Raspberry Pi is a full computer that is not much larger than a credit card, but still packs enough power to be usable as a desktop computer
Aren’t US Treasury Bonds Supposed to be Safe?
How can you lose money selling treasury bonds?
Why Did the Tech Bubble Correspond with Low Interest Rates?
Ultimately, our economy’s deeper problems aren’t so much a result of “money” as they are bad allocations of resources.
What’s Going on at Silicon Valley Bank?
The bank's failure is making a lot of people nervous about their money
The Need for Accountability in AI-Generated Content
Just because we live in a world of AI does not mean we can escape responsibility
Whatever You Do, Don’t Ask GPT for Sources
The chatbot will give you a lot of links that don't necessarily direct you where you want to go
Why ChatGPT Won’t Replace Google
With Google, the algorithm eventually leads you to content made by real people. With ChatGPT, you never leave the algorithm