
A Slightly Technical Introduction to Intelligent Design
Biology, Physics, Mathematics, and Information Theory Original ArticleWhat is Intelligent Design?
Intelligent design — often called “ID” — is a scientific theory that holds that the emergence of some features of the universe and living things is best explained by an intelligent cause rather than an undirected process such as natural selection. ID theorists argue that design can be inferred by studying the informational properties of natural objects to determine if they bear the type of information that in our experience arises from an intelligent cause.
Proponents of neo-Darwinian evolution contend that the information in life arose via purposeless, blind, and unguided processes. ID proponents argue that this information arose via purposeful, intelligently guided processes. Both claims are scientifically testable using the standard methods of science. But ID theorists say that when we use the scientific method to explore nature, the evidence points away from unguided material causes, and reveals intelligent design.
Intelligent Design in Everyday Reasoning
Whether we realize it or not, we detect design constantly in our everyday lives. In fact, our lives often depend on inferring intelligent design. Imagine you are driving along a road and come to a place where the asphalt is covered by a random splatter of paint. You would probably ignore the paint and keep driving onward.
But what if the paint is arranged in the form of a warning? In this case, you would probably make a design inference that could save your life. You would recognize that an intelligent agent was trying to communicate an important message.
Only an intelligent agent can use foresight to accomplish an end-goal — such as building a car or using written words to convey a message. Recognizing this unique ability of intelligent agents allows scientists in many fields to detect design.
Intelligent Design in Archaeology and Forensics
ID is in the business of trying to discriminate between strictly naturally/materially caused objects on the one hand, and intelligently caused objects on the other. A variety of scientific fields already use ID reasoning. For example, archaeologists find an object and they need to determine whether it arrived at its shape through natural processes, so it’s just another rock (let’s say), or whether it was carved for a purpose by an intelligence. Likewise forensic scientists distinguish between naturally caused deaths (by disease, for example), and intelligently caused deaths (murder). These are important distinctions for our legal system, drawing on science and logical inference. Using similar reasoning, intelligent design theorists go about their research. They ask: If we can use science to detect design in other fields, why should it be controversial when we detect it in biology or cosmology?
Here is how ID works. Scientists interested in detecting design start by observing how intelligent agents act when they design things. What we know about human agents provides a large dataset for this. One of the things we find is that when intelligent agents act, they generate a great deal of information. As ID theorist Stephen Meyer says: “Our experience-based knowledge of information-flow confirms that systems with large amounts of specified complexity (especially codes and languages) invariably originate from an intelligent source—from a mind or personal agent.”1
Thus ID seeks to find in nature reliable indications of the prior action of intelligence—specifically it seeks to find the types of information which are known to be produced by intelligent agents. Yet not all “information” is the same. What kind of information is known to be produced by intelligence? The type of information that indicates design is generally called “specified complexity” or “complex and specified information” or “CSI” for short. I will briefly explain what these terms mean.
Something is complex if it is unlikely. But complexity or unlikelihood alone is not enough to infer design. To see why, imagine that you are dealt a five-card hand of poker. Whatever hand you receive is going to be a very unlikely set of cards. Even if you get a good hand, like a straight or a royal flush, you’re not necessarily going to say, “Aha, the deck was stacked.” Why? Because unlikely things happen all the time. We don’t infer design simply because of something’s being unlikely. We need more: specification. Something is specified if it matches an independent pattern.
A Tale of Two Mountains
Imagine you are a tourist visiting the mountains of North America. You come across Mount Rainier, a huge dormant volcano not far from Seattle. There are features of this mountain that differentiate it from any other mountain on Earth. In fact, if all possible combinations of rocks, peaks, ridges, gullies, cracks, and crags are considered, this exact shape is extremely unlikely and complex. But you don’t infer design simply because Mount Rainier has a complex shape. Why? Because you can easily explain its shape through the natural processes of erosion, uplift, heating, cooling, freezing, thawing, weathering, etc. There is no special, independent pattern to the shape of Mount Rainier. Complexity alone is not enough to infer design.
But now let’s say you go to a different mountain—Mount Rushmore in South Dakota. This mountain also has a very unlikely shape, but its shape is special. It matches a pattern—the faces of four famous Presidents. With Mount Rushmore, you don’t just observe complexity, you also find specification. Thus, you would infer that its shape was designed.
ID theorists ask “How can we apply this kind of reasoning to biology?” One of the greatest scientific discoveries of the past fifty years is that life is fundamentally built upon information. It’s all around us. As you read a book, your brain processes information stored in the shapes of ink on the page. When you talk to a friend, you communicate information using sound-based language, transmitted through vibrations in air molecules. Computers work because they receive information, process it, and then give useful output.
Everyday life as we know it would be nearly impossible without the ability to use information. But could life itself exist without it? Carl Sagan observed that the “information content of a simple cell” is “around 1012 bits, comparable to about a hundred million pages of the Encyclopedia Britannica.”2 Information forms the chemical blueprint for all living organisms, governing the assembly, structure, and function at essentially all levels of cells. But where does this information come from?
As I noted previously, ID begins with the observation that intelligent agents generate large quantities of CSI. Studies of the cell reveal vast quantities of information in our DNA, stored biochemically through the sequence of nucleotide bases. No physical or chemical law dictates the order of the nucleotide bases in our DNA, and the sequences are highly improbable and complex. Yet the coding regions of DNA exhibit very unlikely sequential arrangements of bases that match the precise pattern necessary to produce functional proteins. Experiments have found that the sequence of nucleotide bases in our DNA must be extremely precise in order to generate a functional protein. The odds of a random sequence of amino acids generating a functional protein is less than 1 in 10 to the 70th power.3In other words, our DNA contains high CSI.
Thus, as nearly all molecular biologists now recognize, the coding regions of DNA possess a high “information content”—where “information content” in a biological context means precisely “complexity and specificity.” Even the staunch Darwinian biologist Richard Dawkins concedes that “[b]iology is the study of complicated things that give the appearance of having been designed for a purpose.”4 Atheists like Dawkins believe that unguided natural processes did all the “designing” but intelligent design theorist Stephen C. Meyer notes, “in all cases where we know the causal origin of ‘high information content,’ experience has shown that intelligent design played a causal role.”5
A DVD in Search of a DVD Player
But just having the information in our DNA isn’t enough. By itself, a DNA molecule is useless. You need some kind of machinery to read the information in the DNA and produce some useful output. A lone DNA molecule is like having a DVD—and nothing more. A DVD might carry information, but without a machine to read that information, it’s all but useless (maybe you could use it as a Frisbee). To read the information in a DVD, we need a DVD player. In the same way, our cells are equipped with machinery to help process the information in our DNA.
That machinery reads the commands and codes in our DNA much as a computer processes commands in computer code. Many authorities have recognized the computer-like information processing of the cell and the computer-like information-rich properties of DNA’s language-based code. Bill Gates observes, “Human DNA is like a computer program but far, far more advanced than any software we’ve ever created.”6 Biotech guru Craig Venter says that “life is a DNA software system,”7 containing “digital information” or “digital code,” and the cell is a “biological machine” full of “protein robots.”8 Richard Dawkins has written that “[t]he machine code of the genes is uncannily computer-like.”9 Francis Collins, the leading geneticist who headed the human genome project, notes, “DNA is something like the hard drive on your computer,” containing “programming.”10
Cells are thus constantly performing computer-like information processing. But what is the result of this process? Machinery. The more we discover about the cell, the more we learn that it functions like a miniature factory, replete with motors, powerhouses, garbage disposals, guarded gates, transportation corridors, CPUs, and much more. Bruce Alberts, former president of the U.S. National Academy of Sciences, has stated:
[T]he entire cell can be viewed as a factory that contains an elaborate network of interlocking assembly lines, each of which is composed of a set of large protein machines. … Why do we call the large protein assemblies that underlie cell function protein machines? Precisely because, like machines invented by humans to deal efficiently with the macroscopic world, these protein assemblies contain highly coordinated moving parts.11
There are hundreds, if not thousands, of molecular machines in living cells. In discussions of ID, the most famous example of a molecular machine is the bacterial flagellum. The flagellum is a micro-molecular propeller assembly driven by a rotary engine that propels bacteria toward food or a hospitable living environment. There are various types of flagella, but all function like a rotary engine made by humans, as found in some car and boat motors. Flagella also contain many parts that are familiar to human engineers, including a rotor, a stator, a drive shaft, a U-joint, and a propeller. As one molecular biologist writes, “More so than other motors the flagellum resembles a machine designed by a human.”12 But there’s something else that’s special about the flagellum.
Introducing “Irreducible Complexity”
In applying ID to biology, ID theorists often discuss “irreducible complexity,” a concept developed and popularized by Lehigh University biochemist Michael Behe. Irreducible complexity is a form of specified complexity, which exists in systems composed of “several interacting parts that contribute to the basic function, and where the removal of any one of the parts causes the system to effectively cease functioning.”13 Because natural selection only preserves structures that confer a functional advantage to an organism, such systems would be unlikely to evolve through a Darwinian process. Why? Because there is no evolutionary pathway where they could remain functional during each small evolutionary step. According to ID theorists, irreducible complexity is an informational pattern that reliably indicates design, because in all irreducibly complex systems in which the cause of the system is known by experience or observation, intelligent design or engineering played a role in the origin of the system.
Microbiologist Scott Minnich has performed genetic knockout experiments where each gene encoding a flagellar part is mutated individually such that it no longer functions. His experiments show that the flagellum fails to assemble or function properly if any one of its approximately 35 different protein-components is removed.14 By definition, it is irreducibly complex. In this all-or-nothing game, mutations cannot produce the complexity needed to evolve a functional flagellum one step at a time. The odds are also too daunting for it to evolve in one great mutational leap.
The past fifty years of biological research have showed that life is fundamentally based upon:
- A vast amount of complex and specified information encoded in a biochemical language.
- A computer-like system of commands and codes that processes the information.
- Irreducibly complex molecular machines and multi-machine systems.
Where, in our experience, do language, complex and specified information, programming code, and machines come from? They have only one known source: intelligence.
Intelligent Design Extends Beyond Biology
But there’s much more to ID. Contrary to what many people suppose, ID is much broader than the debate over Darwinian evolution. That’s because much of the scientific evidence for intelligent design comes from areas that Darwin’s theory doesn’t even address. In fact, much evidence for intelligent design from physics and cosmology.
The fine-tuning of the laws of physics and chemistry to allow for advanced life is an example of extremely high levels of CSI in nature. The laws of the universe are complex because they are highly unlikely. Cosmologists have calculated the odds of a life-friendly universe appearing by chance are less than 1 in 1010^123. That’s ten raised to a power of 10 with 123 zeros after it—a number far too long to write out! The laws of the universe are specified in that they match the narrow band of parameters required for the existence of advanced life. This high CSI indicates design. Even the atheist cosmologist Fred Hoyle observed, “A common sense interpretation of the facts suggests that a super intellect has monkeyed with physics, as well as with chemistry and biology.”15 From the tiniest atom, to living organisms, to the architecture of the entire cosmos, the fabric of nature shows strong evidence that it was intelligently designed.
Using Mathematics to Detect Design
Intelligent design has its roots in information theory, and design can be detected via statistical mathematical calculations.
As noted, ID theorists begin by observing the types of information produced by the action of intelligent agents vs. the types of information produced through purely natural processes. By making these observations, we can infer that intelligence is the best explanation for many information-rich features we see in nature. But can the inference to design be made rigorously using mathematics? ID theorists think we can, by mathematically quantifying the amount of information present and determining if it is the type of information which, in our experience, is only produced by intelligence.
The fact that information is a real entity is attested by scientists both inside and outside the ID movement. In his essay “Intelligent Design as a Theory of Information,” a pro-ID mathematician and philosopher William Dembski notes:
No one disputes that there is such a thing as information. As Keith Devlin remarks, “Our very lives depend upon it, upon its gathering, storage, manipulation, transmission, security, and so on. Huge amounts of money change hands in exchange for information. People talk about it all the time. Lives are lost in its pursuit. Vast commercial empires are created in order to manufacture equipment to handle it.”16
The fundamental intuition behind measuring information is a reduction in possibilities. The more possibilities you rule out, the more information present. Thus Dembski uses accepted definitions from the field of information theory that define information as the occurrence of one event, or scenario, while excluding other events, or scenarios. In other words, information is what you get when you narrow down what you’re talking about.
The amount of information in a system or represented by some event can be calculating the probability of that scenario, and converting that probability into units of information, called “bits.” These are the same “bits” and “bytes” from the computer world. We can calculate bits according to the following equation:
Given a probability p of some event or scenario, Information content = I = – Log2 (p)
For example, in binary code, each character has two possibilities—0 or 1—meaning the probability of any character is 0.5. Using the formula above, this leads to an information content of 1 bit for each binary digit. Thus, a binary string like “00110” contains 5 bits. But saying “this string carries 5 bits of information” says nothing about the meaning of the string! It only describes the likelihood of the string occurring. Nobel Prize winning molecular biologist Jack Szostak explains that this classical method of measuring information via raw probabilities does not help us discern the functional meaning of an information-rich system:
[C]lassical information theory … does not consider the meaning of a message, defining the information content of a string of symbols as simply that required to specify, store or transmit the string. … A new measure of information—functional information—is required to account for all possible sequences that could potentially carry out an equivalent biochemical function, independent of the structure or mechanism used.17
Szostak suggests that we must look at more than just the likelihood (i.e., the probability or raw information content in bits) to understand the functional workings of natural systems. We must look at the meaning of the information as well. ID theorists feel the same way.
To measure both the information content and the meaning of some event, Dembski developed the concept of complex and specified information (CSI), which was discussed earlier. To review, this method of detecting design can not only determine if an event unlikely (i.e., high information content), but also whether it matches a pre-existing pattern or “specification” (i.e., it has some functional meaning). This is seen in the diagram below:
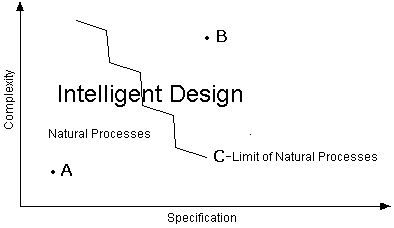
In the figure above, Point A, which bears low CSI, represents something best explained by natural processes. Point B, which has high CSI, represents something best explained by design. Curve C represents the upper limit to what natural processes can produce-the “universal probability bound.” Anything far beyond Curve C is best explained by design; anything far within Curve C is best explained by natural processes.
As seen in figure at above, there is a limit to the amount of CSI which can be produced by natural processes (represented by Curve C). When we see a specified event that is highly unlikely—high CSI—we know that natural processes were not involved, and that intelligent design is the best explanation. When low information content is involved, natural causes can produce the feature in question, and the best explanation is some natural cause.
To help us discriminate between systems that could arise naturally and those that are best explained by design, ID proponents have developed the “universal probability bound,” a measure of the maximum amount of CSI that could be produced during the entire history of the universe. In essence, if the CSI content of a system exceeds the universal probability bound, then natural causes cannot explain that feature and it can only be explained by intelligent design. Dembski and Jonathan Witt explain it this way:
Scientists have learned that within the known physical universe there are about 1080 elementary particles … Scientists also have learned that a change from one state of matter to another can’t happen faster than what physicists call the Planck time. … The Planck time is 1 second divided by 1045 (1 followed by forty-five zeroes). … Finally, scientists estimate that the universe is about fourteen billion years old, meaning the universe is itself millions of times younger than 1025 seconds. If we now assume that any physical event in the universe requires the transition of at least one elementary particle (most events require far more, of course), then these limits on the universe suggest that the total number of events throughout cosmic history could not have exceeded 1080 x 1045 x 1025 = 10150.
This means that any specified event whose probability is less than 1 chance in 10150 will remain improbable even if we let every corner and every moment of the universe roll the proverbial dice. The universe isn’t big enough, fast enough or old enough to roll the dice enough times to have a realistic chance of randomly generating specified events that are this improbable.18
Using our equation for calculating bits, an event whose probability is 1 in 10150 carries about 500 bits of information. This means that if the CSI content of a system is greater than 500 bits, then we can rule out blind material causes and infer intelligent design. Dembski has applied this method to bacterial flagellum, an irreducibly complex molecular machine which contains high CSI, and calculated that it contains a few thousand bits of information—far greater than what can be produced by natural causes according to the universal probability bound.
But ID theorists have developed other ways to research the limits of what can be produced by natural processes, especially in the context of Darwinian evolution.
Intelligent Design and the Limits of Natural Selection
Intelligent design does not reject all aspects of evolution. Evolution can mean something as benign as (1) “life has changed over time,” or it can entail more controversial ideas, like (2) “all living things share common ancestry,” or (3) “natural selection acting upon random mutations produced life’s diversity.”
ID does not conflict with the observation that natural selection causes small-scale changes over time (meaning 1), or the view that all organisms are related by common ancestry (meaning 2). However, the dominant evolutionary viewpoint today is neo-Darwinism (meaning 3), which contends that life’s entire history was driven by unguided natural selection acting on random mutations (as well as other forces like genetic drift)—a collection of blind, purposeless process with no directions or goals. It is this specific neo-Darwinian claim that ID directly challenges.
Darwinian evolution can work fine when one small step (e.g., a single point mutation) along an evolutionary pathway gives an advantage that helps an organisms survive and reproduce. The theory of ID has no problem with this, and acknowledges that there are many small-scale changes that Darwinian mechanisms can produce.
But what about cases where many steps, or multiple mutations, are necessary to gain some advantage? Here, Darwinian evolution faces limits on what it can accomplish. Evolutionary biologist Jerry Coyne affirms this when he states: “natural selection cannot build any feature in which intermediate steps do not confer a net benefit on the organism.”19 Likewise, Darwin wrote in The Origin of Species:
If it could be demonstrated that any complex organ existed, which could not possibly have been formed by numerous, successive, slight modifications, my theory would absolutely break down.
As Darwin’s quote suggests, natural selection gets stuck when a feature cannot be built through “numerous, successive, slight modifications”—that is, when a structure requires multiple mutations to be present before providing any advantage for natural selection to select. Proponents of intelligent design have done research showing that many such biological structures exist which would require multiple mutations before providing some advantage.
In 2004, biochemist Michael Behe co-published a study in Protein Science with physicist David Snoke demonstrating that if multiple mutations were required to produce a functional bond between two proteins, then “the mechanism of gene duplication and point mutation alone would be ineffective because few multicellular species reach the required population sizes.”20
Writing in 2008 in the journal Genetics, Behe and Snoke’s critics tried to refute them, but failed. The critics found that, in a human population, to obtain a feature via Darwinian evolution that required only two mutations before providing an advantage “would take > 100 million years,” which they admitted was “very unlikely to occur on a reasonable timescale.”21 Such “multi-mutation features” are thus unlikely to evolve in humans, which have small population sizes and long generation times, reducing the efficiency of the Darwinian mechanism.
But can Darwinian processes produce complex multimutation features in bacteria which have larger population sizes and reproduce rapidly? Even here, Darwinian evolution faces limits.
In a 2010 peer-reviewed study, molecular biologist Douglas Axe calculated that when a “multi-mutation feature” requires more than six mutations before giving any benefit, it is unlikely to arise even in the whole history of the Earth—even in the case of bacteria.22 He provided empirical backing for this conclusion from experimental research he earlier published in the Journal of Molecular Biology. There, he found there that only one in 1074 amino-acid sequences yields a functional protein fold.23 That implies that protein folds in general are multimutation features, requiring many amino acids to be present before there is any functional advantage.
Another study by Axe and biologist Ann Gauger found that merely converting one enzyme to perform the function of a closely related enzyme—the kind of conversion that evolutionists claim can happen easily—would require a minimum of seven mutations.24 This exceeds the limits of what Darwinian can produce over the Earth’s entire history, as calculated by Axe’s 2010 paper.
A later study published in 2014 by Gauger, Axe and biologist Mariclair Reeves bolstered this finding. They examined additional proteins to determine whether they could be converted via mutation to perform the function of a closely related protein.25 After inducing all possible single mutations in the enzymes, and many other combinations of mutations, they found that evolving a protein, via Darwinian evolution, to perform the function of a closely related protein would take over 1015 years—over 100,000 times longer than the age of the earth!
Collectively, these research results indicate that many biochemical features would require many mutations before providing any advantage to an organism, and would thus be beyond the limit of what Darwinian evolution can do. If blind evolution cannot build these CSI-rich features, what can? Some non-random process is necessary that can “look ahead” and find the complex combinations of mutations to generate these high-CSI features. That process is intelligent design.
A Positive Argument or God of the Gaps?
When arguing against ID, some critics will contend that ID is merely a negative argument against evolution, what some will call a “God-of-the-gaps” argument. A “God-of-the-gaps” argument, critics observe, argues for God based upon gaps in our knowledge, rather than presenting a positive argument. Moreover, it is said that “God-of-the-gaps” arguments are dangerous to faith, because as our knowledge increases, our basis for believing in God is squeezed into smaller and smaller “gaps” in our knowledge. Eventually, the argument goes, there is no reason for believing in God at all. Does ID present a God-of-the-gaps argument? It does not, for many reasons.
First, ID refers to an intelligent cause and does not identify the designer as “God.” All ID scientifically detects is the prior action of an intelligent cause. ID respects the limits of scientific inquiry and does not attempt to address religious questions about the identity of the designer. Indeed, the ID movement includes people of many worldviews, including Christians, Jews, Muslims, people of Eastern religious views, and even agnostics. What unites them is not some religious view about the identity of the designer, but a conviction that there is scientific evidence for intelligent design in nature.
More to the point, the argument for design is not based on what we don’t know (i.e., gaps in our knowledge), but is rather based entirely on what we do know (evidence) about the known causes of information-rich systems. For example, irreducibly complex molecular machines contain high CSI, and we know from experience that high-CSI systems arise from the action of an intelligent agent. To elaborate on a quote given earlier from Stephen Meyer:
[W]e have repeated experience of rational and conscious agents—in particular ourselves—generating or causing increases in complex specified information, both in the form of sequence-specific lines of code and in the form of hierarchically arranged systems of parts. … Our experience-based knowledge of information-flow confirms that systems with large amounts of specified complexity (especially codes and languages) invariably originate from an intelligent source—from a mind or personal agent.26
Similarly, Meyer and biochemist Scott Minnich explain that irreducibly complex systems in particular are always known to derive from an intelligent cause:
Molecular machines display a key signature or hallmark of design, namely, irreducible complexity. In all irreducibly complex systems in which the cause of the system is known by experience or observation, intelligent design or engineering played a role the origin of the system. … Indeed, in any other context we would immediately recognize such systems as the product of very intelligent engineering. Although some may argue this is a merely an argument from ignorance, we regard it as an inference to the best explanation, given what we know about the powers of intelligent as opposed to strictly natural or material causes.27
It’s important to understand that when ID theorists argue that we can find in nature the kind of information and complexity that comes from intelligence, they are not making a mere argument from analogy. When one reduces natural systems to their raw informational properties, they are mathematically identical to those of designed systems. Though not an ID proponent, molecular biologist Hubert Yockey explains that form of information in DNA is identical to what we find in language:
It is important to understand that we are not reasoning by analogy. The sequence hypothesis [that the exact order of symbols records the information] applies directly to the protein and the genetic text as well as to written language and therefore the treatment is mathematically identical.28
Though Yockey is no ID proponent, he rightly observes that the informational properties of DNA are mathematically identical to language. Thus, the argument for design is much stronger than a mere appeal to analogy, and we don’t infer design based upon merely finding and exploiting alleged “gaps” in our knowledge. Rather, ID is based upon the positive argument that nature contains the kind of information and complexity which, in our positive experience, comes only from the action of intelligence. Accordingly, intelligent design is, by standard scientific methods, the best explanation for high CSI in nature.
Using the Scientific Method to Positively Detect Design
As a final demonstration of how ID uses a positive scientific argument, consider how the scientific method can be used to detect design. The scientific method is commonly described as a four-step process involving observation, hypothesis, experiment, and conclusion. ID uses this precise scientific method to make a positive cases for design in various scientific fields, including biochemistry, paleontology, systematics, and genetics:
Example 1—Using the Scientific Method to Detect Design in Biochemistry:
- Observation: Intelligent agents solve complex problems by acting with an end goal in mind, producing high levels of CSI. In our experience, systems with large amounts of CSI—such as codes and languages—invariably originate from an intelligent source. Likewise, in our experience, intelligence is the cause of irreducibly complex machines.
- Hypothesis (Prediction): Natural structures will be found that contain many parts arranged in intricate patterns that perform a specific function—indicating high levels of CSI, including irreducible complexity.
- Experiment: Experimental investigations of DNA indicate that it is full of a CSI-rich, language-based code. Cells use computer-like information processing systems to translate the genetic information in DNA into proteins. Biologists have performed mutational sensitivity tests on proteins and determined that their amino acid sequences are highly specified. The end-result of cellular information processing system are protein-based micromolecular machines. Genetic knockout experiments and other studies show that some molecular machines, like the bacterial flagellum, are irreducibly complex.
- Conclusion: The high levels of CSI—including irreducible complexity—in biochemical systems are best explained by the action of an intelligent agent.
Example 2—Using the Scientific Method to Detect Design in Paleontology:
- Observation: Intelligent agents rapidly infuse large amounts of information into systems. As four ID theorists write: “intelligent design provides a sufficient causal explanation for the origin of large amounts of information… the intelligent design of a blueprint often precedes the assembly of parts in accord with a blueprint or preconceived design plan.”
- Hypothesis (Prediction): Forms containing large amounts of novel information will appear in the fossil record suddenly and without similar precursors.
- Experiment: Studies of the fossil record show that species typically appear abruptly without similar precursors. The Cambrian explosion is a prime example, although there are other examples of explosions in life’s history. Large amounts of CSI had to arise rapidly to explain the abrupt appearance of these forms.
- Conclusion: The abrupt appearance of new fully formed body plans in the fossil record is best explained by intelligent design.
Example 3—Using the Scientific Method to Detect Design in Systematics:
- Observation: Intelligent agents often reuse functional components in different designs. As Paul Nelson and Jonathan Wells explain: “An intelligent cause may reuse or redeploy the same module in different systems… [and] generate identical patterns independently.”
- Hypothesis (Prediction): Genes and other functional parts will be commonly reused in different organisms.
- Experiment: Studies of comparative anatomy and genetics have uncovered similar parts commonly existing in widely different organisms. Examples of extreme convergent evolution show reusage of functional genes and structures in a manner not predicted by common ancestry.
- Conclusion: The reusage of highly similar and complex parts in widely different organisms in non-treelike patterns is best explained by the action of an intelligent agent.
Example 4— Using the Scientific Method to Detect Design in Genetics:
- Observation: Observation: Intelligent agents construct structures with purpose and function. As William Dembski argues: “Consider the term ‘junk DNA.’… [O]n an evolutionary view we expect a lot of useless DNA. If, on the other hand, organisms are designed, we expect DNA, as much as possible, to exhibit function.”
- Hypothesis (Prediction): Much so-called “ junk DNA” will turn out to perform valuable functions.
- Experiment: Numerous studies have discovered functions for “junk DNA.” Examples include functions for pseudogenes, introns, and repetitive DNA.
- Conclusion: The discovery of function for numerous types of “junk DNA” was successfully predicted by intelligent design.
One might disagree with the conclusions of ID, but one cannot reasonably claim that these arguments for design are based upon religion, faith, or divine revelation. They are based upon science.
Follow the Evidence Where It Leads
There will, of course, always be gaps in scientific knowledge. But when critics accuse ID of being a “gaps-based” argument, they essentially insist that all gaps may only be filled with naturalistic explanations, and promote “materialism-of-the-gaps” thinking. This precludes scientists from fully seeking the truth and finding evidence for design in nature. ID rejects gaps-based reasoning of all kinds, and follows the motto that we should “follow the evidence wherever it leads.”
Adding ID to our explanatory toolkit leads to many advances in different scientific fields. In biochemistry, ID allows us to better understand the workings and origin of molecular machines. In paleontology, ID helps resolve long-standing questions about patterns of abrupt appearance—and disappearance—of species. In systematics, ID explains why studies of biomolecules and anatomy are failing to yield a grand “tree of life.” In genetics, ID leads biology into a new paradigm where life is full of functional, information rich molecules containing new layers of code and regulation. In this way, ID is best poised to lead biology into an information age that uncovers the complex, information-based genetic and epigenetic workings of life.
ID has scientific merit because it uses well-accepted methods of historical sciences in order to detect in nature the types of complexity that we understand, from present-day observations, are derived from intelligent causes. From top to bottom, when we study nature through science, we find evidence of fine-tuning and planning—intelligent design—from the macro-architecture of the entire universe to the tiniest submicroscopic biomolecular machines. The more we understand nature, the more clearly we see it is filled with evidence for design.
Good ID Websites for More Information:
- ID Portal: www.intelligentdesign.org
- IDEA Student Clubs: www.ideacenter.org
- ID News Site: www.evolutionnews.org
- ID Podcast: www.idthefuture.com
- Resources for Faith Leaders: www.faithandevolution.org
- Discovery Institute’s ID Program: www.discovery.org/ID
Click here for a printable PDF of this article.
References Cited
[1.] Stephen C. Meyer, “The origin of biological information and the higher taxonomic categories,” Proceedings of the Biological Society of Washington, 117(2):213-239 (2004).
[2.] Carl Sagan, “Life,” in Encyclopedia Britannica: Macropaedia Vol. 10 (Encyclopedia Britannica, Inc., 1984), 894.
[3.] Douglas D. Axe, “Extreme Functional Sensitivity to Conservative Amino Acid Changes on Enzyme Exteriors,” Journal of Molecular Biology, 301:585-595 (2000); Douglas D. Axe, “Estimating the Prevalence of Protein Sequences Adopting Functional Enzyme Folds,” Journal of Molecular Biology, 341: 1295–1315 (2004).
[4.] Richard Dawkins, The Blind Watchmaker (New York: W. W. Norton, 1986), 1.
[5.] Stephen C. Meyer et. al., “The Cambrian Explosion: Biology’s Big Bang,” in Darwinism, Design, and Public Education, J. A. Campbell and S. C. Meyer eds. (Michigan State University Press, 2003).
[6.] Bill Gates, N. Myhrvold, and P. Rinearson, The Road Ahead: Completely Revised and Up-To-Date (Penguin Books, 1996), 228.
[7.] J. Craig Venter, “The Big Idea: Craig Venter On the Future of Life,” The Daily Beast (October 25, 2013), accessed October 25, 2013, www.thedailybeast.com/articles/2013/10/25/the-big-idea-craig-venter-the-future-of-life.html.
[8.] J. Craig Venter, quoted in Casey Luskin, “Craig Venter in Seattle: ‘Life Is a DNA Software System’,” (October 24, 2013), www.evolutionnews.org/2013/10/craig_venter_in078301.html.
[9.] Richard Dawkins, River Out of Eden: A Darwinian View of Life (New York: Basic Books, 1995), 17.
[10.] Francis Collins, The Language of God: A Scientist Presents Evidence for Belief (New York: Free Press, 2006), 91.
[11.] Bruce Alberts, “The Cell as a Collection of Protein Machines: Preparing the Next Generation of Molecular Biologists,” Cell, 92: 291-294 (Feb. 6, 1998).
[12.] David J. DeRosier, “The Turn of the Screw: The Bacterial Flagellar Motor,” Cell, 93: 17-20 (April 3, 1998).
[13.] Michael J. Behe, Darwin’s Black Box: The Biochemical Challenge to Darwinism (Free Press 1996), 39.
[14.] Transcript of testimony of Scott Minnich, Kitzmiller et al. v. Dover Area School Board (M.D. Pa., PM Testimony, November 3, 2005), 103-112. See also Table 1 in R. M. Macnab, “Flagella,” in Escherichia Coli and Salmonella Typhimurium: Cellular and Molecular Biology Vol. 1, eds. F. C. Neidhardt, J. L. Ingraham, K. B. Low, B. Magasanik, M. Schaechter, and H. E. Umbarger (Washington D.C.: American Society for Microbiology, 1987), 73-74.
[15.] Fred Hoyle, “The Universe: Past and Present Reflections,” Engineering and Science, pp. 8-12 (November, 1981).
[16.] William Dembski, “Intelligent Design as a Theory of Information,” Naturalism, Theism and the Scientific Enterprise: An Interdisciplinary Conference at the University of Texas, Feb. 20-23, 1997, http://www.discovery.org/a/118 (citations omitted).
[17.] Jack W. Szostak, “Molecular messages,” Nature, 423: 689 (June 12, 2003).
[18.] William Dembski and Jonathan Witt, Intelligent Design Uncensored, pp. 68-69 (InterVarsity Press, 2010).
[19.] Jerry Coyne, “The Great Mutator,” The New Republic (June 14, 2007).
[20.] Michael Behe and David Snoke, “Simulating Evolution by Gene Duplication of Protein Features That Require Multiple Amino Acid Residues,” Protein Science, 13: 2651-2664 (2004).
[21.] Rick Durrett and Deena Schmidt, “Waiting for Two Mutations: With Applications to Regulatory Sequence Evolution and the Limits of Darwinian Evolution,” Genetics, 180:1501-1509 (2008).
[22.] Douglas Axe, “The Limits of Complex Adaptation: An Analysis Based on a Simple Model of Structured Bacterial Populations,” BIO-Complexity, 2010 (4): 1-10.
[23.] Axe, “Estimating the Prevalence of Protein Sequences Adopting Functional Enzyme Folds”; Axe, “Extreme Functional Sensitivity to Conservative Amino Acid Changes on Enzyme Exteriors.”
[24.] Ann Gauger and Douglas Axe, “The Evolutionary Accessibility of New Enzyme Functions: A Case Study from the Biotin Pathway,” BIO-Complexity, 2011 (1): 1-17.
[25.] Mariclair A. Reeves, Ann K. Gauger, Douglas D. Axe, “Enzyme Families—Shared Evolutionary History or Shared Design? A Study of the GABA-Aminotransferase Family,” BIO-Complexity, 2014 (4): 1-16.
[26.] Meyer, “The origin of biological information and the higher taxonomic categories.”
[27.] Scott A. Minnich & Stephen C. Meyer, “Genetic analysis of coordinate flagellar and type III regulatory circuits in pathogenic bacteria,” in Proceedings of the Second International Conference on Design & Nature, Rhodes Greece, p. 8 (M.W. Collins & C.A. Brebbia eds., 2004).
[28.] Hubert P. Yockey, “Self Organization Origin of Life Scenarios and Information Theory,” Journal of Theoretical Biology, 91:13-31 (1981).
Click here for a printable PDF of this article.
Copyright © 2016. Version 1.0 Permission Granted to Reproduce for Educational Purposes.